Benchmark Trigger. Typically, this node is connected
to the output of a Post Run node to evaluate the just-completed run.
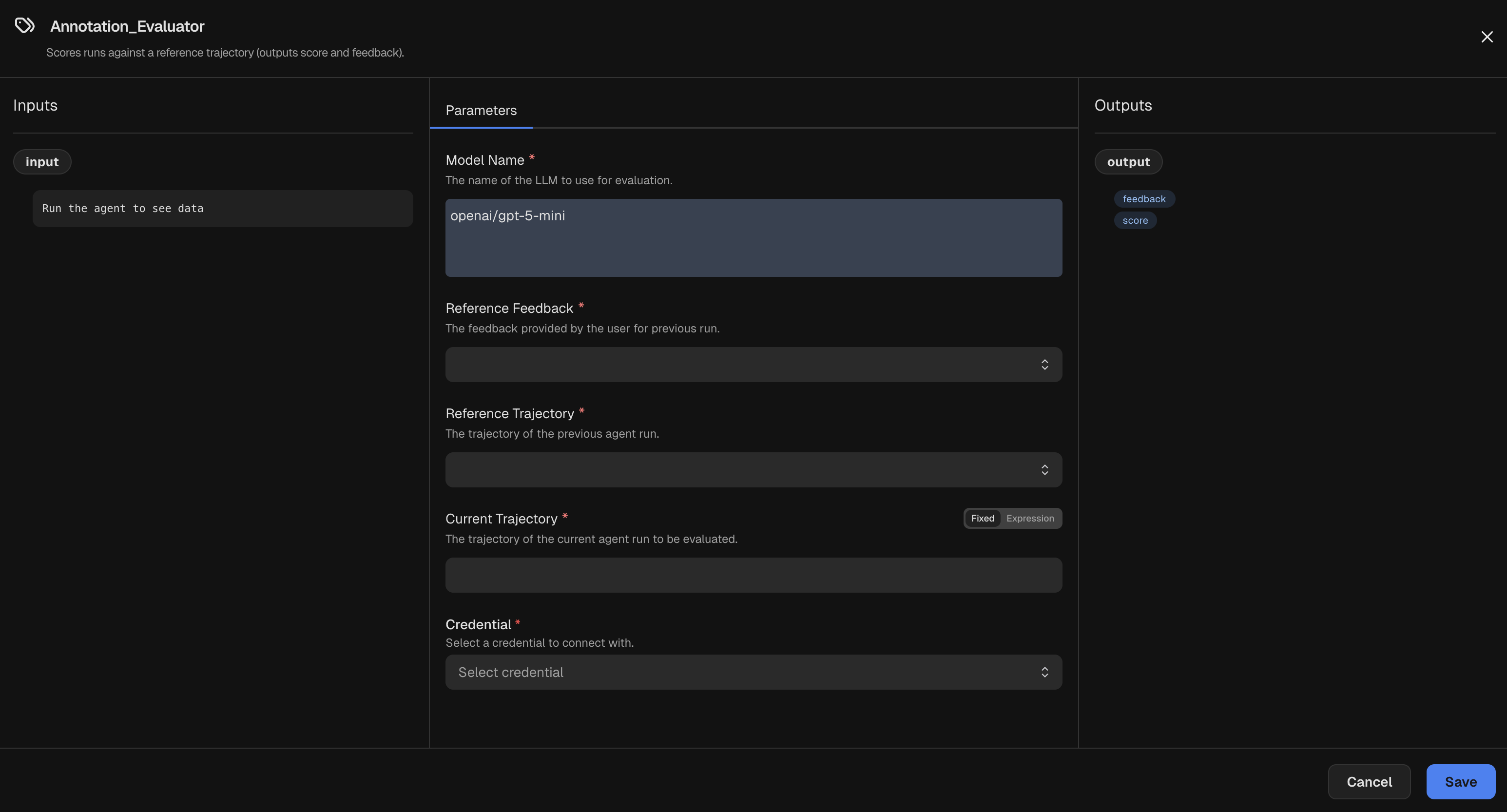
Parameters
LLM used to evaluate the run.
Optional provider API version to use when calling the model.
The level of reasoning effort to use for the LLM, if supported by the model.
Accepted values are
none, minimal, low, medium, high, xhigh, or default.Additional arguments to pass directly to the underlying model’s API.
Feedback for the reference agent run. You can simply select the
Benchmark Trigger
node that supplies this feedback.Trajectory of a reference agent run. You can simply select the
Benchmark Trigger
node that supplies this trajectory.Trajectory of the current run to evaluate. If you have connected this node to a
Post Run node,
you can set this parameter to the expression ${input} to use the output of that node. Otherwise,
you can set this to an expression referring to a Post Run. For example, ${@Post_Run.output}.Credentials
Select an LLM Credential used by the evaluator model.
Inputs
The input passed to the evaluator. Typically, this is the current trajectory from a
Post Run node.Outputs
Evaluation result with score and feedback.
| Field | Description |
|---|---|
score | Numeric score for the evaluation. |
feedback | Natural language feedback for the evaluation. |